
Bài tổng hợp này chúng ta đi sâu vào sử dụng LLM trong graph machine learning (học máy đồ thị), sử dụng LLM để tái tạo các thí nghiệm trong phòng thí nghiệm, kết hợp (ensemble) sức mạnh của các LLM khổng lồ với các mô hình học máy truyền thống, và sử dụng AI để xây dựng một “bản đồ tri thức” dưới dạng đồ thị.
Graph Machine Learning in the Era of Large Language Models (LLMs)
Dữ liệu đồ thị xuất hiện ở khắp mọi nơi, từ mạng xã hội (người dùng là nút, quan hệ là cạnh), đồ thị tri thức, đến cấu trúc phân tử. Để khai thác dữ liệu đồ thị, Graph ML đã phát triển mạnh mẽ. GNNs trở thành kỹ thuật tiêu chuẩn nhờ cơ chế “truyền thông điệp” (message-passing), cho phép mỗi nút học hỏi thông tin từ các nút lân cận, từ đó nắm bắt được các mối quan hệ phức tạp trong cấu trúc đồ thị.
Gần đây, LLMs đã cho thấy khả năng vượt trội trong các tác vụ ngôn ngữ. Các tác giả nêu bật tiềm năng của việc tích hợp hai lĩnh vực này.
- LLMs cho Graph ML: LLMs có thể hiểu và xử lý các đặc trưng dạng văn bản của các nút (ví dụ: mô tả sản phẩm, nội dung bài báo) tốt hơn nhiều so-t-với các phương pháp truyền thống. Điều này giúp tạo ra các biểu diễn (representation) nút chất lượng hơn cho các mô hình GNN.
- Đồ thị cho LLMs: LLMs dù mạnh mẽ vẫn gặp vấn đề về “ảo giác” (tạo ra thông tin sai sự thật) và hoạt động như một “hộp đen”. Đồ thị tri thức, với các sự thật được lưu trữ một cách có cấu trúc, có thể cung cấp kiến thức nền đáng tin cậy để LLMs dựa vào, từ đó cải thiện tính chính xác và khả năng giải thích.
Các công trình liên quan
Học máy trên Đồ thị (Graph Machine Learning)
Mục tiêu cơ bản của Graph ML: Làm thế nào để máy tính có thể “hiểu” được thông tin chứa trong một đồ thị? Đồ thị bao gồm các nút (nodes) và các cạnh (edges) kết nối chúng. Con người có thể nhìn vào một mạng xã hội và hiểu ai là người có ảnh hưởng, nhóm bạn nào thân thiết. Nhưng máy tính chỉ thấy các con số và ma trận.
Bài toán cốt lõi là học biểu diễn (representation learning): chuyển đổi mỗi nút trong đồ thị thành một vector số (còn gọi là embedding). Vector này phải nắm bắt được cả đặc trưng (features) của nút đó (ví dụ: tuổi, sở thích của một người dùng) và vị trí, vai trò của nó trong cấu trúc đồ thị (ví dụ: nó có nhiều kết nối không, nó là cầu nối giữa các cộng đồng nào). Lịch sử phát triển của Graph ML chính là hành trình tìm ra những cách ngày càng tốt hơn để tạo ra các vector biểu diễn này.
Giai đoạn 1: Các phương pháp “Nhúng Đồ thị” (Graph Embedding) sơ khai
Đây là thế hệ đầu tiên, tập trung chủ yếu vào việc mã hóa cấu trúc đồ thị. Ý tưởng chính là: “hai nút có vị trí tương tự trong đồ thị thì nên có vector biểu diễn gần nhau trong không gian vector”.
Phương pháp “Random Walks” (Đi bộ ngẫu nhiên)
Đây là một kỹ thuật đột phá, lấy cảm hứng từ xử lý ngôn ngữ tự nhiên (NLP).
- Ý tưởng trực quan: ưởng tượng một người đi bộ lang thang trên đồ thị, di chuyển từ nút này sang nút khác thông qua các cạnh. Những con đường (chuỗi các nút) mà người này đi qua sẽ tiết lộ thông tin về cấu trúc lân cận của đồ thị. Những nút thường xuyên xuất hiện cùng nhau trong các cuộc đi bộ ngẫu nhiên có khả năng là có liên quan mật thiết.
- Cách hoạt động (ví dụ với DeepWalk):
- Tạo “câu”: Bắt đầu từ mỗi nút trong đồ thị, thực hiện nhiều cuộc đi bộ ngẫu nhiên với một độ dài nhất định. Mỗi cuộc đi bộ tạo ra một chuỗi các nút, ví dụ: [Nút A, Nút C, Nút D, Nút F]. Chuỗi này được xem như một “câu”.
- Sử dụng mô hình Word2Vec: Các nhà nghiên cứu nhận ra rằng chuỗi nút này rất giống một câu trong ngôn ngữ tự nhiên. Họ sử dụng một thuật toán NLP nổi tiếng là Word2Vec (cụ thể là mô hình Skip-Gram) để học vector cho mỗi “từ” (ở đây “từ” chính là một nút). Mô hình Word2Vec học cách dự đoán các nút lân cận (ngữ cảnh) cho một nút cho trước trong các chuỗi đi bộ.
- Kết quả: Sau khi huấn luyện, mỗi nút sẽ có một vector biểu diễn. Những nút có vai trò cấu trúc tương tự (ví dụ: cùng nằm trong một cộng đồng dày đặc) sẽ có các vector gần nhau.
- Các mô hình tiêu biểu:
- DeepWalk: Là mô hình tiên phong, sử dụng các cuộc đi bộ ngẫu nhiên hoàn toàn.
- Node2Vec: Là một cải tiến quan trọng của DeepWalk. Thay vì đi bộ hoàn toàn ngẫu nhiên, Node2Vec giới thiệu các cuộc “đi bộ thiên vị” (biased random walks). Nó có hai tham số (p và q) để điều khiển cuộc đi bộ:
- Nó có xu hướng quay lại nút vừa đi qua không? (khám phá chiều sâu – local).
- Hay nó có xu hướng khám phá các nút hàng xóm mới, đi ra xa hơn? (khám phá chiều rộng – global).
- Sự linh hoạt này giúp Node2Vec nắm bắt được các sắc thái cấu trúc phức tạp hơn so với DeepWalk.
- Hạn chế của giai đoạn này:
- Không sử dụng đặc trưng của nút: Các phương pháp này gần như chỉ dựa vào cấu trúc kết nối, bỏ qua các thông tin hữu ích có sẵn ở các nút (ví dụ: văn bản trong một bài báo, hình ảnh trên profile).
- Tính “suy diễn chuyển tiếp” (Transductive): Chúng chỉ có thể tạo ra vector cho những nút đã có trong đồ thị lúc huấn luyện. Nếu có một nút mới xuất hiện (ví dụ: người dùng mới đăng ký mạng xã hội), chúng không thể tạo vector cho nút đó mà phải huấn luyện lại từ đầu trên toàn bộ đồ thị.
Giai đoạn 2: Cuộc Cách mạng Học sâu – Mạng Nơ-ron Đồ thị (GNNs)
GNNs ra đời để khắc phục những hạn chế của thế hệ trước, đánh dấu một bước nhảy vọt về khả năng và tính linh hoạt.
- Ý tưởng cốt lõi: “Truyền thông điệp” (Message Passing) hay “Tổng hợp lân cận” (Neighborhood Aggregation)
- Thay vì học một vector tĩnh cho mỗi nút, GNNs học một hàm (function) để tạo ra vector.
- Cách hoạt động: GNN hoạt động theo từng lớp (layer). Ở mỗi lớp:
- Thu thập (Gather): Mỗi nút “nhìn” sang các nút hàng xóm trực tiếp của nó và thu thập vector biểu diễn của chúng từ lớp trước.
- Tổng hợp (Aggregate): Nút đó tổng hợp thông tin từ các hàng xóm lại bằng một hàm nào đó (ví dụ: lấy trung bình, lấy max).
- Cập nhật (Update): Nút đó kết hợp thông tin vừa tổng hợp được với vector của chính nó để tạo ra một vector biểu diễn mới cho lớp hiện tại.
- Hiệu ứng: Sau khi đi qua K lớp GNN, vector biểu diễn của một nút sẽ chứa đựng thông tin từ tất cả các nút trong “vùng lân cận K-bước nhảy” của nó.
- Các mô hình tiêu biểu:
- GCN (Graph Convolutional Network): Là một trong những mô hình GNN đầu tiên và phổ biến nhất. Hàm tổng hợp của nó rất đơn giản: lấy trung bình có trọng số của các vector của hàng xóm và của chính nó. Nó hoạt động hiệu quả trên các đồ thị “đồng nhất” (nơi các nút kết nối với nhau thường có đặc điểm tương tự).
- GraphSAGE (Graph SAmple and aggreGatE): Một cải tiến lớn giải quyết vấn đề “transductive”. Thay vì lấy tất cả hàng xóm, GraphSAGE chỉ lấy mẫu (sample) một số lượng hàng xóm cố định. Quan trọng hơn, nó học một hàm tổng hợp (aggregator function) linh hoạt (có thể là mean, max-pooling, hoặc thậm chí là một mạng nơ-ron nhỏ như LSTM). Vì nó học một hàm, nó có thể được áp dụng cho các nút mới hoặc thậm chí các đồ thị hoàn toàn mới mà không cần huấn luyện lại. Đây được gọi là khả năng “suy diễn quy nạp” (Inductive).
- GAT (Graph Attention Network): Cải tiến hơn nữa hàm tổng hợp. GAT cho rằng không phải hàng xóm nào cũng quan trọng như nhau. Nó sử dụng cơ chế “chú ý” (attention) để học một trọng số cho mỗi hàng xóm. Khi tổng hợp, các hàng xóm quan trọng hơn sẽ có đóng góp lớn hơn. Điều này giúp mô hình linh hoạt và mạnh mẽ hơn.
Giai đoạn 3: Kỷ nguyên của Transformer trên Đồ thị
Mặc dù GNNs rất mạnh mẽ, chúng vẫn có một số hạn chế như khó nắm bắt các mối quan hệ ở khoảng cách rất xa trên đồ thị (long-range dependencies). Kiến trúc Transformer, vốn đã thống trị NLP và thị giác máy tính, được điều chỉnh để giải quyết vấn đề này.
- Ý tưởng cốt lõi: Cơ chế “tự chú ý” (self-attention) của Transformer cho phép mỗi phần tử trong một chuỗi có thể kết nối trực tiếp với mọi phần tử khác.
- Cách hoạt động trên đồ thị: Thay vì chỉ truyền thông điệp đến các hàng xóm gần, Graph Transformer cho phép một nút có thể “chú ý” đến tất cả các nút khác trong đồ thị, bất kể khoảng cách. Điều này giúp nó nắm bắt được cấu trúc toàn cục của đồ thị ngay từ lớp đầu tiên.
- Thách thức: Việc tính toán sự chú ý giữa tất cả các cặp nút rất tốn kém (độ phức tạp O(N²)), vì vậy các nhà nghiên cứu đang tìm cách làm cho nó hiệu quả hơn, thường bằng cách kết hợp thông tin cấu trúc đồ thị vào cơ chế chú ý.
Tóm tắt lịch sử phát triển của Graph ML. Bắt đầu từ các phương pháp sơ khai như “Random Walks” để học biểu diễn nút (ví dụ: DeepWalk, Node2Vec). Sau đó là sự thống trị của các mô hình học sâu như GCN, GraphSAGE, GAT, những mô hình này hiệu quả hơn trong việc học các mẫu phức tạp. Gần đây hơn, kiến trúc Transformer cũng đã được điều chỉnh để xử lý dữ liệu đồ thị.
Mô hình Nền tảng (Foundation Models – FMs)
Mô hình Nền tảng là gì?
Hãy tưởng tượng quá trình học của con người:
- Cách học truyền thống (Trước đây): Để trở thành một bác sĩ, bạn học chuyên về y. Để trở thành một kỹ sư, bạn học chuyên về kỹ thuật. Mỗi ngành nghề đòi hỏi một quá trình đào tạo riêng biệt từ đầu.
- Cách học của Mô hình Nền tảng (Hiện nay): Hãy tưởng tượng một người đã đọc toàn bộ sách trong thư viện lớn nhất thế giới, hiểu biết về mọi lĩnh vực từ văn học, lịch sử, vật lý, đến nghệ thuật. Người này có một nền tảng kiến thức cực kỳ rộng lớn. Bây giờ:
- Nếu bạn muốn người này trở thành một nhà phê bình văn học, bạn chỉ cần đưa cho họ một vài khóa học ngắn về cách viết bài phê bình. Họ sẽ nhanh chóng trở thành chuyên gia vì họ đã có sẵn kiến thức nền về văn học.
- Nếu bạn muốn người này trở thành một nhà tư vấn tài chính, bạn chỉ cần dạy họ các nguyên tắc tài chính cụ thể. Họ sẽ học rất nhanh vì họ đã hiểu về kinh tế, lịch sử thị trường, v.v.
Mô hình Nền tảng trong AI cũng hoạt động tương tự. Nó là một mô hình AI khổng lồ, đóng vai trò như người đã đọc hết thư viện kia. Nó được “dạy” (tiền huấn luyện) trên một lượng dữ liệu khổng lồ và đa dạng (ví dụ: toàn bộ văn bản trên Internet) để xây dựng một “nền tảng” hiểu biết chung về thế giới.
Các đặc tính cốt lõi của Mô hình Nền tảng
Quy mô lớn (Large Scale)
- Về kiến trúc: Các mô hình này có số lượng tham số (parameters) cực lớn, thường từ hàng tỷ đến hàng nghìn tỷ. Tham số có thể được coi như các “nơ-ron” nhân tạo trong bộ não của mô hình, nơi kiến thức được lưu trữ. Kích thước lớn cho phép chúng học và ghi nhớ các mẫu vô cùng phức tạp.
- Về tài nguyên: Để huấn luyện các mô hình này cần đến sức mạnh tính toán khổng lồ, thường là hàng nghìn GPU hoặc TPU chạy liên tục trong nhiều tuần hoặc nhiều tháng.
Tiền huấn luyện (Pre-training) trên dữ liệu khổng lồ
- Học tự giám sát (Self-supervised learning): Thay vì cần con người gán nhãn cho dữ liệu (ví dụ: nói cho máy biết đây là ảnh con mèo, đây là câu văn tích cực), mô hình tự tạo ra bài toán cho chính nó từ dữ liệu thô.
- Ví dụ với GPT: Nhiệm vụ của nó là đọc một đoạn văn bản và dự đoán từ tiếp theo. Bằng cách lặp đi lặp lại nhiệm vụ này hàng tỷ lần trên kho văn bản khổng lồ, nó dần học được ngữ pháp, ngữ nghĩa, các sự kiện, và cả khả năng suy luận.
- Ví dụ với BERT: Nhiệm vụ của nó là điền vào chỗ trống trong một câu (giống trò chơi điền từ). Để làm được điều này, nó phải hiểu ngữ cảnh của cả câu, cả phía trước và phía sau chỗ trống.
- Kết quả của tiền huấn luyện: Mô hình học được một biểu diễn nội tại (internal representation) rất phong phú và tổng quát về dữ liệu.
Khả năng thích ứng & Tinh chỉnh (Adaptability & Fine-tuning)
Đây chính là sức mạnh thực sự của Mô hình Nền tảng.
- Một mô hình, nhiều ứng dụng: Thay vì phải xây dựng một mô hình AI từ đầu cho mỗi tác vụ riêng biệt (dịch máy, tóm tắt văn bản, phân tích cảm xúc), giờ đây chúng ta có thể lấy một Mô hình Nền tảng đã được tiền huấn luyện.
- Quá trình tinh chỉnh: Chúng ta chỉ cần lấy một lượng nhỏ dữ liệu có nhãn dành riêng cho tác vụ của mình (ví dụ: vài nghìn cặp câu dịch Việt-Anh) và huấn luyện tiếp (tinh chỉnh) mô hình trên đó. Quá trình này rất nhanh và hiệu quả vì mô hình không phải học lại từ đầu; nó chỉ cần “chuyên môn hóa” kiến thức nền tảng của mình cho tác vụ mới.
Các ví dụ điển hình
- Xử lý ngôn ngữ (NLP):
- GPT (Generative Pre-trained Transformer): Được tiền huấn luyện để dự đoán từ tiếp theo. Sau khi tinh chỉnh, nó có thể làm các tác vụ như viết văn, trả lời câu hỏi, lập trình.
- BERT (Bidirectional Encoder Representations from Transformers): Được tiền huấn luyện để điền từ vào chỗ trống. Sau khi tinh chỉnh, nó cực kỳ giỏi trong các tác vụ hiểu ngôn ngữ như phân loại văn bản, nhận dạng thực thể.
- Thị giác máy tính (Computer Vision):
- CLIP (Contrastive Language–Image Pre-training): Được tiền huấn luyện trên hàng trăm triệu cặp (hình ảnh, mô tả văn bản) từ Internet. Nó học cách liên kết hình ảnh với ý nghĩa của nó. Nó có thể phân loại một hình ảnh vào một danh mục hoàn toàn mới mà không cần được huấn luyện trên danh mục đó (zero-shot classification).
- DALL-E: Cũng được huấn luyện trên các cặp hình ảnh-văn bản, nhưng nó học theo chiều ngược lại: từ một mô tả văn bản, nó có thể tạo ra một hình ảnh hoàn toàn mới.
Mô hình Nền tảng cho Đồ thị (Graph Foundation Models – GFM)
Đây là phần kết nối lại với bài báo.
- Thách thức lớn: Việc xây dựng một GFM khó hơn nhiều so với NLP hay thị giác. Tại sao?
- Tính không đồng nhất (Heterogeneity): Văn bản về cơ bản là một chuỗi các từ. Hình ảnh là một lưới các pixel. Chúng có cấu trúc đồng nhất. Ngược lại, đồ thị rất đa dạng: mạng xã hội có cấu trúc khác hẳn mạng lưới phân tử, đồ thị tri thức lại có cấu trúc khác. Kích thước, mật độ, loại nút và loại cạnh đều vô cùng khác nhau. Không có một “định dạng chung” cho tất cả các loại đồ thị.
- Thiếu dữ liệu tiền huấn luyện: Không có một “Internet của các đồ thị” khổng lồ, công khai và đa dạng như kho văn bản hay hình ảnh để có thể tiền huấn luyện một mô hình GFM thực sự tổng quát.
- Tại sao GFM vẫn còn ở “giai đoạn sơ khai”: Chính vì những thách thức trên, việc tạo ra một mô hình nền tảng duy nhất có thể “hiểu” mọi loại đồ thị và dễ dàng tinh chỉnh cho các tác vụ cụ thể vẫn đang là một bài toán mở.
- Hướng đi đầy hứa hẹn: Tích hợp LLMs: Đây là luận điểm chính của bài báo. Thay vì cố gắng xây dựng một GFM từ con số không, chúng ta có thể tận dụng sức mạnh của các Mô hình Nền tảng đã có, cụ thể là LLMs.
- LLMs có thể hoạt động như một “bộ mã hóa đặc trưng” (feature encoder) cực mạnh. Rất nhiều đồ thị trong thực tế có các nút chứa thông tin văn bản (ví dụ: nội dung tweet, tóm tắt bài báo khoa học, mô tả sản phẩm). LLMs có thể chuyển đổi các văn bản này thành các vector biểu diễn ngữ nghĩa phong phú, cung cấp đầu vào chất lượng cao cho các mô hình đồ thị.
- LLMs cung cấp một “giao diện chung”. Chúng ta có thể mô tả cấu trúc và thuộc tính của bất kỳ đồ thị nào bằng ngôn ngữ tự nhiên. Điều này có thể giúp giải quyết vấn đề về tính không đồng nhất, cho phép một mô hình duy nhất xử lý các loại đồ thị khác nhau thông qua các “prompt” văn bản.
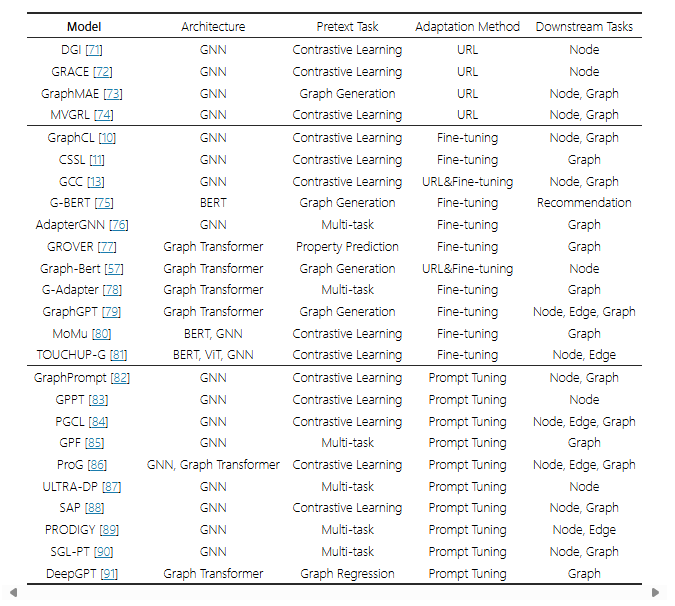
Học sâu trên Đồ thị (Deep Learning on Graphs)
Kiến trúc cốt lõi (Backbone Architecture):
- Mô hình dựa trên tổng hợp lân cận (Neighborhood Aggregation-based Model): Đây là kiến trúc GNN phổ biến nhất, hoạt động bằng cách mỗi nút thu thập thông tin từ các nút hàng xóm và cập nhật biểu diễn của chính nó. Các mô hình như GCN, GraphSAGE, GAT thuộc loại này. Khi bạn xếp chồng nhiều lớp GNN, thông tin sẽ được lan truyền ra xa hơn.
- Sau 1 lớp, mỗi nút học được từ hàng xóm cách nó 1 bước nhảy.
- Sau 2 lớp, mỗi nút học được từ hàng xóm của hàng xóm, tức là các nút cách nó 2 bước nhảy.
- Sau K lớp, mỗi nút sẽ chứa thông tin từ toàn bộ “vùng lân cận K bước nhảy” của nó.
Hãy tưởng tượng thông tin lan truyền như tin đồn trong một ngôi làng.
- Bạn (một nút) muốn biết một tin tức.
- Vòng 1 (Lớp 1): Bạn hỏi những người hàng xóm ngay cạnh nhà bạn. Bạn tổng hợp các mẩu tin họ kể và cập nhật hiểu biết của mình.
- Vòng 2 (Lớp 2): Những người hàng xóm của bạn cũng làm điều tương tự với hàng xóm của họ. Khi bạn hỏi lại hàng xóm của mình ở vòng này, bạn sẽ gián tiếp nghe được tin tức từ những người ở xa hơn.
Các “phiên bản động cơ” tiêu biểu
- GCN (Graph Convolutional Network): Phiên bản “dân chủ”. Nó tổng hợp thông tin bằng cách lấy trung bình có trọng số của tất cả hàng xóm và chính nó. Đơn giản, hiệu quả, nhưng giả định rằng mọi hàng xóm đều quan trọng như nhau.
- GraphSAGE (Graph SAmple and aggreGatE): Phiên bản “thực tế”. Thay vì lấy tất cả hàng xóm (tốn kém với các nút có hàng triệu kết nối), nó chỉ lấy mẫu một số lượng nhất định. Nó cũng học một hàm tổng hợp phức tạp hơn. Quan trọng nhất, nó có thể tạo biểu diễn cho các nút mới xuất hiện mà không cần huấn luyện lại.
- GAT (Graph Attention Network): Phiên bản “tinh tế”. Nó nhận ra rằng không phải hàng xóm nào cũng quan trọng như nhau. GAT sử dụng cơ chế “chú ý” (attention) để tự động học một “trọng số quan trọng” cho mỗi hàng xóm. Khi tổng hợp, những hàng xóm quan trọng hơn sẽ có tiếng nói lớn hơn.
Hạn chế chính
- “Làm mịn quá mức” (Over-smoothing): Đây là vấn đề lớn nhất. Nếu bạn xếp chồng quá nhiều lớp GNN (ví dụ: 10-15 lớp), thông tin sẽ bị “trung bình hóa” quá nhiều. Quay lại ví dụ tin đồn, sau khi qua miệng 15 người, tin đồn ban đầu sẽ trở nên rất chung chung và mất đi chi tiết đặc trưng. Tương tự, biểu diễn của tất cả các nút trong đồ thị sẽ trở nên rất giống nhau, làm cho mô hình không thể phân biệt được chúng.
- Khó nắm bắt các mối quan hệ ở xa (Long-range Dependencies): Thông tin phải di chuyển từng bước một. Để một nút ở đầu này của đồ thị ảnh hưởng đến một nút ở đầu kia, nó cần đi qua rất nhiều lớp, và tín hiệu sẽ bị yếu dần đi trên đường đi.
- Mô hình dựa trên Transformer (Graph Transformer-based Model): Lấy cảm hứng từ thành công của Transformer trong NLP, các mô hình này sử dụng cơ chế “tự chú ý” (self-attention) để nắm bắt các mối quan hệ toàn cục trên đồ thị, giải quyết một số hạn chế của các mô hình tổng hợp lân cận. Thay vì chỉ nhìn vào các hàng xóm gần, Graph Transformer cho phép một nút có thể kết nối và trao đổi thông tin với bất kỳ nút nào khác trong toàn bộ đồ thị, ngay từ lớp đầu tiên.
- Đối với mỗi nút, mô hình sẽ tính toán một “điểm chú ý” (attention score) giữa nút đó và tất cả các nút khác trong đồ thị.
- Điểm số này thể hiện mức độ liên quan hoặc quan trọng của nút kia đối với nút hiện tại, bất kể chúng có được kết nối trực tiếp bằng một cạnh hay không.
- Sau đó, biểu diễn của mỗi nút được cập nhật bằng cách lấy tổng có trọng số của biểu diễn của tất cả các nút khác, với trọng số chính là các điểm chú ý đã được chuẩn hóa.
Quay lại ví dụ ngôi làng. Thay vì đi hỏi từng hàng xóm, bạn tổ chức một cuộc họp toàn làng.
- Mọi người (tất cả các nút) đều có mặt.
- Khi bạn (một nút) nói, tất cả mọi người khác đều lắng nghe và tự quyết định xem ý kiến của bạn quan trọng với họ đến mức nào.
- Bằng cách này, một người ở cuối làng có thể ảnh hưởng trực tiếp đến một người ở đầu làng ngay lập tức, không cần thông tin phải lan truyền qua nhiều người trung gian.
Thách thức
- Chi phí tính toán khổng lồ: Việc tính toán điểm chú ý giữa mỗi nút với tất cả các nút khác có độ phức tạp là O(N²), với N là số nút. Điều này khiến nó không khả thi đối với các đồ thị khổng lồ như mạng xã hội có hàng tỷ nút. Các nghiên cứu hiện tại đang tìm cách làm cho cơ chế chú ý này trở nên hiệu quả hơn (ví dụ: chỉ chú ý đến một tập hợp con các nút quan trọng).
- Có thể bỏ qua cấu trúc cục bộ: Vì nó coi đồ thị như một “tập hợp” các nút, đôi khi nó có thể không tận dụng tốt thông tin cấu trúc cục bộ tinh vi mà các GNN truyền thống làm rất tốt.
- Mô hình Tổng hợp Lân cận giống như một chuyên gia về “tin tức địa phương”. Nó rất hiệu quả trong việc nắm bắt các mẫu trong phạm vi gần, có thể mở rộng và là nền tảng của hầu hết các ứng dụng GNN hiện nay.
- Mô hình Graph Transformer giống như một người có “tầm nhìn chiến lược toàn cục”. Nó có khả năng nhìn thấy bức tranh lớn và các mối liên kết ở xa, nhưng lại tốn kém hơn và đôi khi bỏ lỡ các chi tiết nhỏ.
Học tự giám sát trên Đồ thị (Self-Supervised Learning on Graphs)
Ý tưởng cốt lõi là: “Hãy để dữ liệu tự dạy cho chính nó.” Thay vì cần con người cung cấp nhãn, chúng ta có thể thiết kế các bài toán “giả” (pretext tasks) mà mô hình có thể học từ cấu trúc và đặc trưng vốn có của dữ liệu.
- Tác vụ tiền huấn luyện (Pretext Tasks): Các mô hình GNN học các biểu diễn hữu ích bằng cách thực hiện các tác vụ “giả” không cần nhãn. – Học tương phản (Contrastive Learning): Đây là phương pháp SSL phổ biến và mạnh mẽ nhất.
- Mục tiêu: Huấn luyện mô hình để nó nhận ra “ai là bạn, ai là người lạ”. Cụ thể, vector biểu diễn của những nút/đồ thị “tương tự” nhau nên ở gần nhau, còn vector của những nút/đồ thị “khác biệt” thì phải ở xa nhau trong không gian vector.
- Cách hoạt động:
- Tạo “cặp song sinh” (Positive Pairs): Chúng ta không có nhãn để biết hai nút nào là tương tự. Vì vậy, chúng ta tự tạo ra một phiên bản “song sinh” của một nút bằng cách làm xáo trộn (augment) nó một chút. Ví dụ, với một nút A, chúng ta tạo ra phiên bản A’ bằng cách:
- Xóa ngẫu nhiên một vài cạnh kết nối với nó.
- Che đi một vài phần trong đặc trưng văn bản của nó.
- => Cặp (A, A’) được coi là một cặp “tương tự” (positive pair). Logic là: một nút vẫn là chính nó dù có vài thay đổi nhỏ.
- Tạo “người lạ” (Negative Pairs): Điều này rất dễ. Chúng ta chỉ cần lấy nút A và một nút B hoàn toàn ngẫu nhiên khác trong đồ thị. Cặp (A, B) được coi là một cặp “khác biệt” (negative pair).
- Huấn luyện: Mô hình GNN được huấn luyện để tối thiểu hóa khoảng cách giữa các vector của cặp (A, A’) và tối đa hóa khoảng cách giữa các vector của cặp (A, B). Bằng cách lặp lại điều này hàng triệu lần, mô hình buộc phải học ra những đặc tính cốt lõi, bất biến của một nút, những thứ không bị thay đổi bởi các xáo trộn nhỏ.
- Tạo “cặp song sinh” (Positive Pairs): Chúng ta không có nhãn để biết hai nút nào là tương tự. Vì vậy, chúng ta tự tạo ra một phiên bản “song sinh” của một nút bằng cách làm xáo trộn (augment) nó một chút. Ví dụ, với một nút A, chúng ta tạo ra phiên bản A’ bằng cách:
-Học tạo sinh (Generative Learning): Huấn luyện mô hình bằng cách cho nó chơi trò “điền vào chỗ trống” hoặc “ghép hình”.
- Cách hoạt động:
- “Làm hỏng” dữ liệu: Chúng ta cố tình làm hỏng đồ thị theo một cách nào đó.
- Che đặc trưng (Attribute Masking): Lấy một nút, che đi một phần đặc trưng của nó (ví dụ, xóa một vài từ trong tóm tắt bài báo). Nhiệm vụ của mô hình là dự đoán lại phần đặc trưng đã bị che, dựa vào các nút hàng xóm và phần đặc trưng còn lại.
- Che cạnh (Link Prediction): Xóa bỏ một số cạnh trong đồ thị. Nhiệm-vụ của mô hình là nhìn vào hai nút bất kỳ và dự đoán xem liệu có nên tồn tại một cạnh kết nối giữa chúng hay không.
- Huấn luyện: Mô hình được huấn luyện để dự đoán càng chính xác càng tốt. Để làm được điều này, nó phải học được mối quan hệ sâu sắc giữa cấu trúc đồ thị và đặc trưng của các nút.
- “Làm hỏng” dữ liệu: Chúng ta cố tình làm hỏng đồ thị theo một cách nào đó.
- Thích ứng với tác vụ sau (Downstream Adaptation): Sau khi tiền huấn luyện, mô hình được điều chỉnh cho các tác vụ cụ thể. – Tinh chỉnh (Fine-tuning)
- Cách hoạt động:
- Gắn thêm một “cái đầu” (Output Head): Chúng ta lấy mô hình GNN đã được tiền huấn luyện và gắn thêm một lớp mạng nơ-ron nhỏ ở cuối, ví dụ một lớp phân loại (classification layer).
- Huấn luyện tiếp: Chúng ta sử dụng bộ dữ liệu có nhãn (nhưng lần này chỉ cần một lượng nhỏ) để huấn luyện toàn bộ hệ thống (cả phần GNN cũ và cái đầu mới). Thường thì chúng ta sẽ dùng một tốc độ học (learning rate) rất nhỏ để mô hình không “quên” đi những kiến thức quý giá đã học được trong giai đoạn tiền huấn luyện.
- Ưu/Nhược điểm:
- Ưu điểm: Thường đạt được độ chính xác cao nhất.
- Nhược điểm: Phải lưu một bản sao đầy đủ của mô hình lớn cho mỗi tác vụ, rất tốn dung lượng.
– “Điều chỉnh bằng Gợi ý” (Prompt-tuning): Đây là một phương pháp mới và hiệu quả hơn, lấy cảm hứng từ các mô hình ngôn ngữ lớn (LLMs).
- Giống như một chuyên gia đa năng (mô hình GNN tiền huấn luyện) không cần học lại. Để giải quyết một vấn đề mới, bạn chỉ cần đưa cho họ một bản hướng dẫn (prompt) ngắn gọn. Chuyên gia sẽ đọc hướng dẫn và áp dụng kiến thức sẵn có của mình để giải quyết vấn đề.
- Cách hoạt động:
- ĐÓNG BĂNG (FREEZE) mô hình: Đây là điểm khác biệt cốt lõi. Toàn bộ trọng số của mô hình GNN tiền huấn luyện được giữ nguyên, không thay đổi.
- Học một “Prompt”: Chúng ta tạo ra một vài vector nhỏ, gọi là “prompt”, và chỉ huấn luyện các vector này. Các vector “prompt” này được chèn vào quá trình tính toán của mô hình, hoạt động như những chỉ dẫn để “lái” mô hình GNN đã bị đóng băng thực hiện tác vụ mới.
- Huấn luyện: Chỉ có các vector prompt nhỏ bé này được cập nhật.
- Ưu/Nhược điểm:
- Ưu điểm: Cực kỳ hiệu quả về mặt tham số. Bạn chỉ cần lưu một mô hình lớn và nhiều “prompt” nhỏ cho các tác vụ khác nhau, tiết kiệm rất nhiều dung lượng và thời gian huấn luyện.
- Nhược điểm: Đôi khi độ chính xác có thể thấp hơn một chút so với fine-tuning toàn bộ mô hình.
- Cách hoạt động:
LLMs cho các mô hình Đồ thị (LLMs for Graph Models)
Nâng cao chất lượng đặc trưng (Enhancing Feature Quality):
- Cải thiện biểu diễn đặc trưng: LLMs được dùng như một bộ mã hóa văn bản (text encoder) mạnh mẽ để chuyển đổi các thuộc tính văn bản của nút (tiêu đề, tóm tắt) thành các vector biểu diễn ngữ nghĩa phong phú. Để xử lý các đặc trưng dạng văn bản (ví dụ: tóm tắt của một bài báo, mô tả của một sản phẩm), người ta thường dùng các phương pháp “nông” (shallow) như Bag-of-Words, TF-IDF, hoặc các mô hình nhúng từ (word embedding) nhỏ như Word2Vec. Các phương pháp này có thể nắm bắt được từ khóa nhưng lại bỏ lỡ ngữ cảnh, sắc thái và ý nghĩa sâu xa của câu chữ. LLMs (như BERT, RoBERTa) đã được tiền huấn luyện trên một lượng văn bản khổng lồ từ Internet. Chúng có khả năng hiểu ngôn ngữ một cách sâu sắc và có ngữ cảnh.
- Cách hoạt động: Chúng ta đưa đoạn văn bản (tiêu đề, mô tả) của một nút vào LLM. LLM sẽ hoạt động như một bộ mã hóa văn bản (text encoder) cực kỳ mạnh mẽ, chuyển đổi đoạn văn bản đó thành một vector số (embedding).
- Kết quả: Vector này không chỉ chứa thông tin về từ khóa, mà còn chứa đựng ngữ nghĩa phong phú. Ví dụ, nó có thể phân biệt được “Apple” (công ty) và “apple” (quả táo) dựa vào ngữ cảnh. Vector này sau đó được dùng làm đặc trưng đầu vào chất lượng cao cho mô an hình GNN, giúp GNN có một khởi đầu tốt hơn rất nhiều.
- Tạo ra thông tin bổ sung: Sử dụng khả năng tạo sinh của LLMs để tạo thêm các thuộc tính hữu ích. Ví dụ, từ tiêu đề một bộ phim, LLM có thể tạo ra thông tin về đạo diễn, quốc gia, thể loại. Một nút trong đồ thị phim chỉ có mỗi tên phim “The Matrix”. Chúng ta có thể khai thác khả năng tạo sinh (generative) của các LLMs như GPT. Nó hoạt động như một “cỗ máy tri thức” có thể bổ sung thông tin.
- Cách hoạt động: Chúng ta tạo ra một “gợi ý” (prompt) cho LLM. Ví dụ: “Dựa trên tên phim ‘The Matrix’, hãy cung cấp thông tin về đạo diễn, diễn viên chính, thể loại, và một tóm tắt ngắn về nội dung.”
- Kết quả: LLM sẽ tạo ra một đoạn văn bản chi tiết. Đoạn văn bản mới, giàu thông tin này sau đó được đưa qua bộ mã hóa (như ở mục a) để tạo ra một vector đặc trưng hoàn chỉnh hơn rất nhiều cho nút “The Matrix”. Điều này giúp mô hình GNN hiểu được mối liên hệ giữa “The Matrix” và “John Wick” (cùng diễn viên Keanu Reeves) một cách dễ dàng hơn.
- Căn chỉnh không gian đặc trưng: Trong thực tế, các nút đồ thị thường đa phương thức (multi-modal), tức là chứa nhiều loại dữ liệu khác nhau. Ví dụ, một nút sản phẩm trên Amazon có: mô tả (văn bản), hình ảnh, và video đánh giá. Mỗi loại dữ liệu này khi được mã hóa sẽ nằm trong một “không gian vector” khác nhau, giống như những người nói các ngôn ngữ khác nhau, rất khó để kết hợp.Các mô hình LLM đa phương thức (như CLIP của OpenAI) được thiết kế để giải quyết chính xác vấn đề này. Chúng được huấn luyện để hiểu mối liên hệ giữa hình ảnh và văn bản.
- Cách hoạt động: Chúng ta có thể dùng một mô hình như CLIP để mã hóa cả hình ảnh sản phẩm và mô tả văn bản. Mô hình này sẽ tạo ra các vector sao cho vector của hình ảnh và vector của văn bản mô tả nó sẽ ở gần nhau trong cùng một không gian biểu diễn chung.
- Kết quả: Chúng ta có được một vector đặc trưng thống nhất, kết hợp thông tin từ nhiều phương thức. GNN giờ đây có thể học từ một biểu diễn toàn diện hơn, giúp nó đưa ra các gợi ý chính xác hơn.
Giải quyết các hạn chế khi huấn luyện GNN (Solving Vanilla GNN Training Limitations): LLMs có thể thực hiện các tác vụ trên đồ thị mà không cần huấn luyện GNN, giúp giảm sự phụ thuộc vào dữ liệu có nhãn. Các phương pháp được phân loại dựa trên cách chúng xử lý cấu trúc đồ thị:
- Bỏ qua thông tin cấu trúc: LLM chỉ dựa vào đặc trưng văn bản của nút mục tiêu để đưa ra dự đoán (ví dụ: phân loại một bài báo chỉ dựa vào tiêu đề và tóm tắt của nó).
- Ví dụ: Để phân loại một bài báo khoa học, ta chỉ đưa tiêu đề và tóm tắt của nó vào LLM và hỏi: “Bài báo này thuộc lĩnh vực nào?”. Nó không quan tâm bài báo này trích dẫn ai hay được ai trích dẫn.
- Đánh giá: Phương pháp này hoạt động như một đường cơ sở (baseline) để xem chỉ riêng nội dung văn bản có thể làm được gì. Nó không thực sự là “học trên đồ thị”.
- Sử dụng cấu trúc ngầm định: Cấu trúc đồ thị (thông tin về các nút lân cận) được mô tả bằng ngôn ngữ tự nhiên và đưa vào “prompt” của LLM.
- Cách tiếp cận: Chúng ta “dạy” cho LLM về cấu trúc đồ thị bằng cách mô tả nó bằng ngôn ngữ tự nhiên trong prompt.
- Cách hoạt động: Cấu trúc lân cận của một nút được chuyển thành một đoạn văn bản và đưa vào cùng với câu hỏi.
- Ví dụ: “Tôi đang xem xét nút A trong một mạng lưới. Nút A được kết nối với nút B và nút C. Đặc trưng của nút A là […], đặc trưng của nút B là […], đặc trưng của nút C là […]. Dựa vào thông tin này, hãy dự đoán nhãn cho nút A.”
- Đánh giá: Mạnh hơn cách tiếp cận bỏ qua cấu trúc. Tuy nhiên, nó bị giới hạn bởi độ dài của prompt (context window). Nếu một nút có hàng nghìn hàng xóm, không thể mô tả hết chúng trong prompt.
- Sử dụng cấu trúc tường minh: Một mô hình GNN được sử dụng để mã hóa cấu trúc đồ thị thành một vector. Vector này sau đó được kết hợp với thông tin văn bản và đưa vào LLM để suy luận. Đây là cách kết hợp sâu nhất.
- Cách tiếp cận: Đây là phương pháp kết hợp “những gì tốt nhất của cả hai thế giới”. Mỗi mô hình sẽ làm đúng công việc sở trường của nó.
- Phân chia nhiệm vụ:
- GNN: Chuyên xử lý cấu trúc. Nó nhận đầu vào là toàn bộ đồ thị và tạo ra một “vector cấu trúc” cho mỗi nút. Vector này tóm tắt vị trí và vai trò của nút trong mạng lưới.
- LLM: Chuyên xử lý ngữ nghĩa và suy luận.
- Cách hoạt động:
- Một mô hình GNN (có thể đã được tiền huấn luyện) chạy trên đồ thị để tạo ra các vector cấu trúc.
- Vector cấu trúc này được kết hợp (fused) với vector đặc trưng văn bản (tạo ra bởi LLM).
- Vector kết hợp cuối cùng được đưa vào LLM để đưa ra dự đoán cuối cùng.
- Đánh giá: Đây là phương pháp mạnh mẽ và linh hoạt nhất, vì nó tận dụng được sức mạnh xử lý cấu trúc hiệu quả của GNN và khả năng hiểu ngữ nghĩa sâu sắc của LLM.
Tính không đồng nhất và Khả năng tổng quát hóa (Heterophily and Generalization):
Xử lý đồ thị “không đồng nhất” (Heterophily)
- Vấn đề: Các GNN truyền thống hoạt động tốt nhất trên các đồ thị “đồng nhất” (homophily), nơi các nút được kết nối thường có đặc điểm giống nhau (ví dụ: bạn bè trên mạng xã hội thường có cùng sở thích). Chúng gặp khó khăn trên đồ thị không đồng nhất, nơi các nút kết nối lại khác nhau (ví dụ: trong một trang thương mại điện tử, người mua hàng và sản phẩm là hai loại nút khác nhau nhưng lại kết nối với nhau).
- Giải pháp với LLMs: LLMs ít bị ảnh hưởng bởi vấn đề này. Chúng tập trung vào ý nghĩa ngữ nghĩa của mối quan hệ. Dù nút “người mua” và nút “sản phẩm” là khác loại, LLM có thể hiểu được mối quan hệ “mua hàng” dựa trên nội dung văn bản của chúng. Nó hiểu rằng một người dùng có lịch sử mua “tiểu thuyết khoa học viễn tưởng” sẽ có khả năng kết nối với một sản phẩm sách mới cũng thuộc thể loại đó.
Cải thiện khả năng tổng quát hóa (Generalization)
- Vấn đề: Một mô hình GNN được huấn luyện để phân tích mạng xã hội không thể được dùng ngay để phân tích cấu trúc phân tử. Chúng quá khác biệt.
- Giải pháp với LLMs: LLMs cung cấp một “giao diện phổ quát” thông qua ngôn ngữ tự nhiên. Chúng ta có thể mô tả bất kỳ loại đồ thị nào dưới dạng văn bản.
- Đối với phân tử, chúng ta có thể dùng chuỗi SMILES để mô tả cấu trúc.
- Đối với mạng xã hội, chúng ta mô tả các mối quan hệ bạn bè.
- Kết quả: Cùng một LLM, chỉ cần thay đổi prompt, có thể được áp dụng cho các loại đồ thị và tác vụ hoàn toàn khác nhau. Điều này mở đường cho việc xây dựng các mô hình nền tảng cho đồ thị (Graph Foundation Models) thực sự linh hoạt và có khả năng tổng quát hóa cao.
[Còn tiếp]
Bạn có thể đọc thêm nội dung chi tiết của bài này trên trang substack [cần trả phí].