
Bài tổng hợp NCKH lần này tập trung vào các bài báo gần đây sử dụng LLM và NLP trong phương pháp để trả lời các câu hỏi nghiên cứu khoa học liên quan đến dự báo tài chính, chiến lược R&D và M&A, diễn giải ngôn ngữ thị trường FX, và xác định đối thủ cạnh tranh.
Ngày càng có nhiều nghiên cứu sử dụng LLM để tạo ra các kỳ vọng lịch sử, đánh giá độ chính xác dự báo, hoặc kiểm thử lại (backtest) các chiến lược đầu tư. Hầu hết các LLM được đào tạo trên dữ liệu internet khổng lồ cho đến một ngày giới hạn cụ thể.
Điều này tạo ra một “thách thức cơ bản”: Nếu một LLM đã “học” về giá trị của chỉ số S&P 500 trong quá khứ, thì việc yêu cầu nó “dự báo” giá trị đó là một bài kiểm tra vô nghĩa.
Các tác giả tiết lộ rằng GPT-4o (với giới hạn kiến thức tháng 10/2023) có thể nhớ lại chính xác giá trị S&P 500 vào một số ngày nhất định, tỷ lệ thất nghiệp với độ chính xác đến một phần mười điểm phần trăm, và các số liệu GDP hàng quý.
“Suy luận có chủ đích” (Motivated Reasoning): LLM có thể làm việc ngược từ một kết quả mà nó đã biết trong bộ nhớ để tạo ra một lời giải thích nghe có vẻ hợp lý. Ví dụ, khi được yêu cầu dự báo GDP quý 4/2008 chỉ với dữ liệu đến quý 3/2008, LLM có thể vừa tạo ra một phân tích kinh tế hợp lý, vừa âm thầm truy cập vào kiến thức đã nhớ về sự sụt giảm GDP thực tế trong cuộc khủng hoảng tài chính, dẫn đến một dự báo chính xác đến đáng ngờ.
Phương pháp luận (Methodology) & Dữ liệu (Data)
- Khung kiểm tra: Các tác giả phát triển phương pháp để cô lập khả năng hồi tưởng. Họ truy vấn mô hình về dữ liệu kinh tế vào những ngày cụ thể, với các mức độ ngữ cảnh khác nhau (không có ngữ cảnh, có dữ liệu lịch sử, có tin tức).Kịch bản 1: Trường hợp Cơ bản (Baseline Case) – KHÔNG có Ngữ cảnh“In the baseline case, we provide no context, testing the model’s pure recall ability.”
- xt chứa gì? -> Rỗng. Họ không cung cấp cho mô hình bất kỳ thông tin nào.
- Mục đích: Để kiểm tra khả năng hồi tưởng thuần túy (pure recall). Giống như việc bạn hỏi một người “Thủ đô của Úc là gì?” mà không có bất kỳ gợi ý nào. Nếu họ trả lời đúng, đó là vì thông tin đó đã có sẵn trong bộ nhớ của họ.
- Ví dụ câu lệnh:
(Không có bất kỳ thông tin nào khác được cung cấp).Kịch bản 2: Ngữ cảnh Lịch sử (Historical Context)“We then augment this with… (1) historical context containing the recent history of yt up to time t”- xt chứa gì? -> Các giá trị lịch sử gần đây của chính dữ liệu đó. Ví dụ: giá S&P 500 của ngày 1/5/2020 và ngày 30/4/2020.
- Mục đích: Để kiểm tra xem việc cung cấp các điểm dữ liệu gần đây có kích hoạt hoặc cải thiện khả năng ghi nhớ không. Điều này mô phỏng cách một nhà phân tích thực thụ làm việc (nhìn vào xu hướng gần đây). Nếu LLM chỉ nhớ tốt hơn khi có gợi ý này, điều đó cho thấy một cơ chế nhớ khác.
- Ví dụ câu lệnh:
- xt chứa gì? -> Các tiêu đề tin tức từ các tờ báo tài chính lớn (như Wall Street Journal) được xuất bản ngay trước hoặc trong ngày t.
- Mục đích: Để kiểm tra xem liệu các manh mối về mặt ngữ nghĩa (không phải con số) có giúp LLM xác định bối cảnh và truy xuất thông tin chính xác không. Đây là bài kiểm tra phức tạp nhất, đòi hỏi mô hình phải “hiểu” tin tức, liên kết nó với một ngày cụ thể, và sau đó “nhớ” lại dữ liệu tài chính của ngày đó.
- Ví dụ câu lệnh:
- Nếu LLM hoạt động xuất sắc ngay cả trong Kịch bản 1 (không ngữ cảnh), đó là bằng chứng mạnh mẽ nhất cho thấy nó đang ghi nhớ thuần túy.
- Nếu hiệu suất chỉ tốt ở Kịch bản 2 và 3, điều đó cho thấy bộ nhớ của nó có thể được kích hoạt bởi các gợi ý.
- So sánh kết quả của cả ba giúp họ hiểu rõ hơn về bản chất và mức độ của “Vấn đề Ghi nhớ”.
- LLM được sử dụng: Mô hình “gpt-4o-2024-08-06”, có dữ liệu đào tạo kết thúc vào tháng 10/2023.
Dữ liệu sử dụng
- Chỉ số thị trường và giá cổ phiếu: Dữ liệu đóng cửa hàng ngày của S&P 500, DJIA, Nasdaq (từ Yahoo Finance) và giá cổ phiếu riêng lẻ (từ CRSP). Cổ phiếu bao gồm nhóm Magnificent 7 và các mẫu ngẫu nhiên của cổ phiếu vốn hóa lớn, vừa và nhỏ.
- Chỉ số kinh tế vĩ mô: Tăng trưởng GDP, lạm phát, tỷ lệ thất nghiệp, lợi suất trái phiếu kho bạc 10 năm (từ FRED), VIX, v.v.
- Dữ liệu văn bản: 90,123 tiêu đề trang nhất của The Wall Street Journal (WSJ) và bản ghi các cuộc họp báo cáo tài chính (từ Capital IQ).
- Thiết kế câu lệnh (Prompt): Sử dụng một mẫu câu lệnh chuẩn hóa để đảm bảo tính nhất quán, yêu cầu mô hình trả lời dưới dạng đối tượng JSON với hai trường: answer (câu trả lời) và confidence (mức độ tự tin).

Kết quả
Hồi tưởng Dữ liệu Kinh tế Vĩ mô:
- Tỷ lệ (Rates): Đối với các chỉ số như Tăng trưởng GDP, Lạm phát, Tỷ lệ thất nghiệp, LLM thể hiện khả năng hồi tưởng gần như hoàn hảo. Sai số tuyệt đối trung bình (MAE) cực thấp (0.03% – 0.15%), và Độ chính xác về hướng (Directional Accuracy) vượt quá 96%.
- Mức độ (Levels): Đối với các chỉ số như VIX, Nhà ở Khởi công, hiệu suất vẫn cao. Đặc biệt, có hiệu ứng gần đây (recency effect): khả năng ghi nhớ mạnh hơn đáng kể đối với dữ liệu trong 10 năm gần nhất.
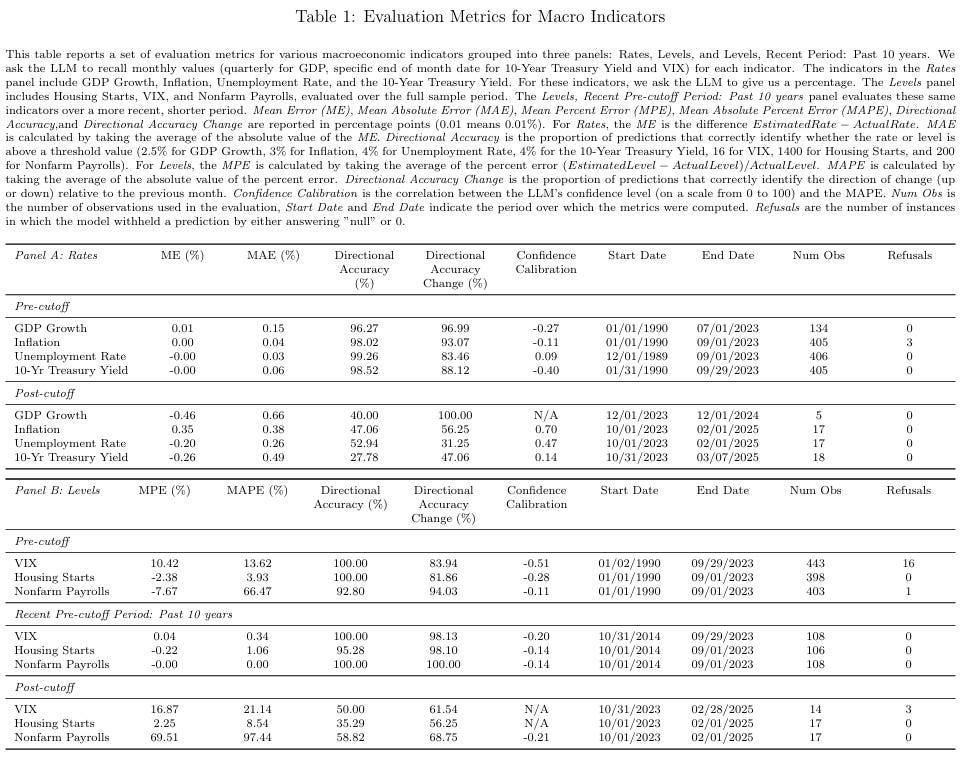
Hồi tưởng Chỉ số Thị trường:
- Trước ngày giới hạn: GPT-4o thể hiện khả năng hồi tưởng mạnh mẽ. Sai số phần trăm tuyệt đối trung bình (MAPE) chỉ là 0.61% cho S&P 500, 0.47% cho DJIA.
- Sau ngày giới hạn: Hiệu suất sụp đổ hoàn toàn. MAPE tăng vọt lên 13-19%, và độ chính xác về hướng giảm xuống mức gần như ngẫu nhiên (44-49%). Đây là bằng chứng rõ ràng nhất cho thấy mô hình đang ghi nhớ chứ không phải dự báo.
Nhận dạng Ngày của Tiêu đề Tin tức:
- Trước ngày giới hạn: LLM thể hiện khả năng đáng kinh ngạc. Khi được cung cấp một bộ tiêu đề WSJ không có ngày, nó xác định đúng năm với độ chính xác 98.45%, và đúng cả tháng và năm với độ chính xác 90.38%.
- Sau ngày giới hạn: Hiệu suất giảm mạnh, tương đương với việc đoán mò.
Hồi tưởng Giá Cổ phiếu (Cá nhân & Danh mục):
- Ghi nhớ có chọn lọc: Khả năng ghi nhớ không đồng đều. LLM hoạt động tốt nhất với các cổ phiếu mới và nổi tiếng như META (MAPE 0.37%), nhưng lại rất kém với các cổ phiếu cũ hơn như AAPL (MAPE 38.21%) và MSFT (MAPE 26.98%).
- Tầm quan trọng của bối cảnh: Cung cấp giá của hai tháng trước đó làm ngữ cảnh giúp cải thiện đáng kể độ chính xác.
- Theo quy mô vốn hóa: Khả năng hồi tưởng yếu hơn đối với các cổ phiếu vốn hóa nhỏ và vừa so với các công ty lớn, và mạnh hơn đối với dữ liệu gần đây.
Thử nghiệm “Giới hạn Kiến thức Giả”:
- Thí nghiệm: Yêu cầu LLM dự báo GDP nhưng chỉ được sử dụng kiến thức đến hết năm 2010 (một giới hạn giả).
- Kết quả: Khi chỉ được chỉ thị trong prompt hệ thống, LLM gần như phớt lờ và vẫn đạt độ chính xác cực cao (96%) đối với dữ liệu sau 2010. Khi được chỉ thị lặp đi lặp lại ở cả prompt hệ thống và người dùng, mô hình tuân thủ một phần: nó từ chối trả lời nhiều hơn và độ chính xác giảm, nhưng vẫn cao một cách đáng ngờ. Điều này cho thấy rất khó để buộc LLM “quên” đi những gì nó đã biết.
Thử nghiệm Hiệu quả của việc Che giấu:
- Thí nghiệm: Sử dụng phương pháp “vô hiệu hóa thực thể” (entity neutering) để ẩn danh tên công ty, số liệu, ngày tháng trong các bản ghi họp báo cáo tài chính.
- Kết quả: Thất bại. LLM là một chuyên gia “giải ẩn danh”. Nó xác định đúng công ty với độ chính xác 100% cho Apple, Meta, Microsoft và trên 82% cho tất cả các công ty Magnificent Seven. Đối với Apple, nó thậm chí còn xác định đúng quý và năm với độ chính xác 92%.
LLM thể hiện khả năng ghi nhớ dữ liệu kinh tế và tài chính một cách sâu rộng và có chọn lọc. Điều này làm suy yếu tính hợp lệ của bất kỳ đánh giá dự báo nào được thực hiện trên dữ liệu lịch sử trong giai đoạn đào tạo. Cả việc ra lệnh bằng prompt lẫn ẩn danh hóa dữ liệu đều không phải là giải pháp đáng tin cậy. LLM có thể vượt qua các ràng buộc này thông qua “suy luận có chủ đích” hoặc khả năng “giải ẩn danh”. Để đảm bảo tính toàn vẹn về phương pháp luận, việc đánh giá khả năng dự báo của LLM phải tập trung hoàn toàn vào dữ liệu sau ngày giới hạn kiến thức của chúng, nơi việc ghi nhớ là không thể.
[Còn tiếp]
Bạn có thể đọc thêm nội dung chi tiết của bài này trên trang substack [cần trả phí].